Unlock Communication. Instantly.
A revolutionary real-time visual speech recognition system, empowering individuals with hearing and speech impairments through advanced AI lipreading technology.
Discover LIP-TRACIntroducing LIP-TRAC: Your Window to Conversation
LIP-TRAC translates lip movements into text, bridging communication gaps with a design philosophy centered on real-world performance and accessibility.

LIP-TRAC prototype on Raspberry Pi 5
Understand speech as it happens.
With an average inference time of just ~6.3 seconds on low-cost hardware, LIP-TRAC keeps conversations flowing naturally without frustrating delays.
No more guessing what was said.
Achieving a Word Error Rate under 33%, LIP-TRAC far surpasses the ~70% WER of typical human lipreading, providing reliable and accurate transcriptions.
Clarity in chaos.
As a purely visual system, LIP-TRAC is immune to background noise, crowded rooms, or poor acoustics, making it a dependable tool where audio-based systems fail.
A tool for everyone.
Designed for individuals with hearing loss, conditions like Aphonia, or for anyone needing to communicate in complete silence.
Affordability meets innovation.
Breaking the cost barrier of traditional assistive devices, our lightweight model is optimized to run efficiently on accessible hardware like the Raspberry Pi 5.
How It Works: From Pixels to Prose
LIP-TRAC employs a sophisticated, multi-stage AI pipeline to transform visual data into accurate text, all optimized for efficiency.
Step 1: Automatic Lip Region Cropping
A Haar Cascade classifier first identifies the speaker's face. The model then intelligently isolates the mouth region, which contains the most crucial visual cues for speech.

Step 2: Data Preparation & Downsampling
The cropped 160x160px color image is converted to a 40x120px grayscale frame. This 16x data reduction drastically cuts computational load while retaining essential features.

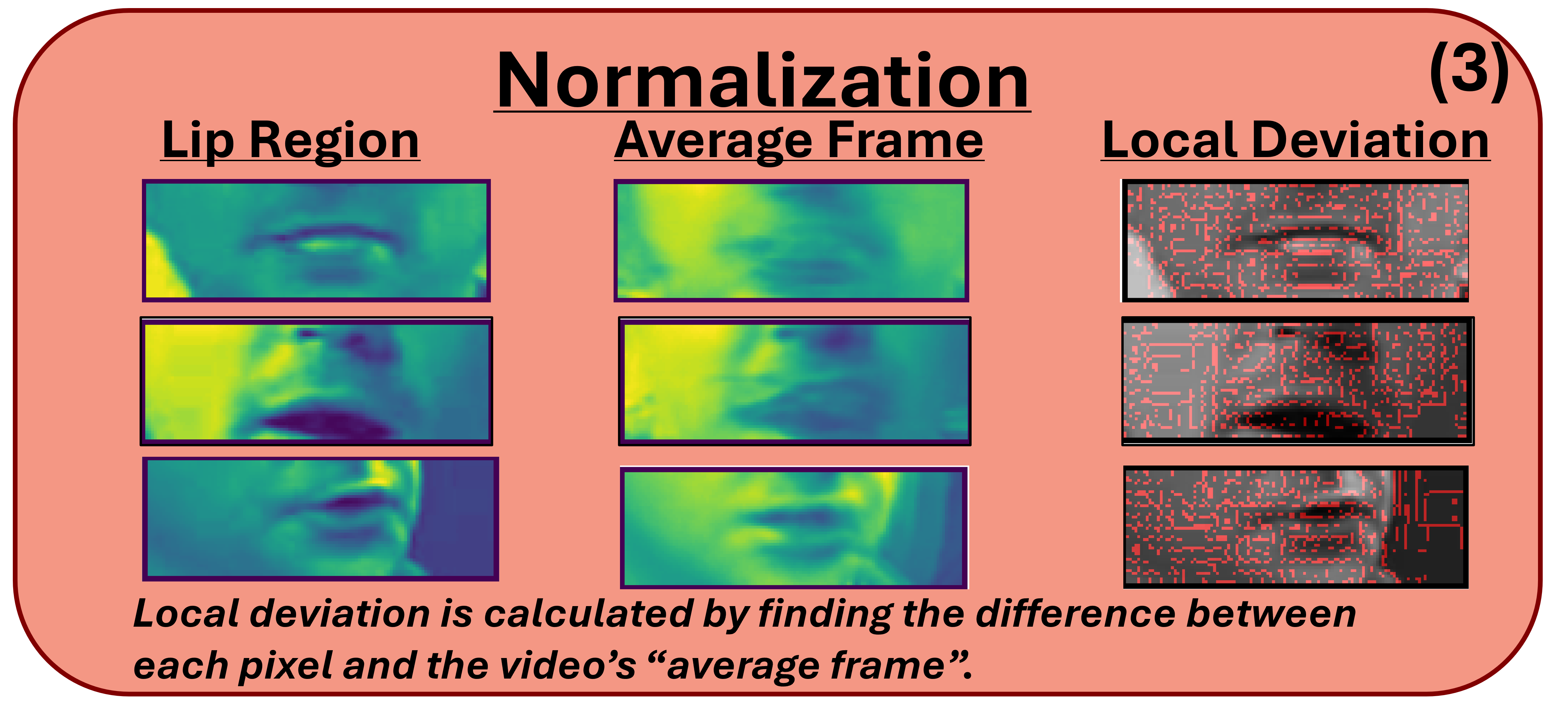
Step 3: Frame Normalization
To handle variations in lighting and speaker appearance, each frame's pixel values are normalized against the video's average frame, highlighting the dynamic lip movements.
Step 4: Capturing Temporal Changes
A 3D Convolutional Neural Network (CNN) processes sequences of frames, learning the spatiotemporal patterns that correspond to different phonemes and words.
Step 5: Model Training
The CRNN model was trained on an NVIDIA RTX 3060 Ti across 300 epochs, using the LRS2 dataset and a Connectionist Temporal Classification (CTC) loss function.

Step 6: Optimization & Deployment
Key parameters like learning rate and architecture choices (GRU vs. LSTM) were optimized for an ideal balance of speed and accuracy, enabling deployment on the Raspberry Pi 5.

Explore the Research
Dive deeper into the technical innovations, data-driven results, and market context behind the LIP-TRAC project.
Full Research Paper
The definitive source on methodology, experiments, and detailed results.
Conference Poster
A visual summary of the project's objectives, methods, and key findings.
Market Analysis
An analysis of the "Deployment Gap" and LIP-TRAC's technological landscape.
The Future of LIP-TRAC
The journey doesn't end here. We are actively exploring the next frontiers of visual speech recognition.
Audio-Visual Fusion
Integrating a lightweight audio stream to create a multi-modal system that excels in both noisy and quiet environments.
Lexical Correction
Implementing word-level prediction with dictionaries to improve the coherence and accuracy of transcribed sentences.
Contextual Understanding
Utilizing N-Gram language models to better predict word sequences based on grammatical and conversational context.
Multi-Lingual Expansion
Training and testing the architecture on new datasets to support multiple languages, dialects, and accents globally.